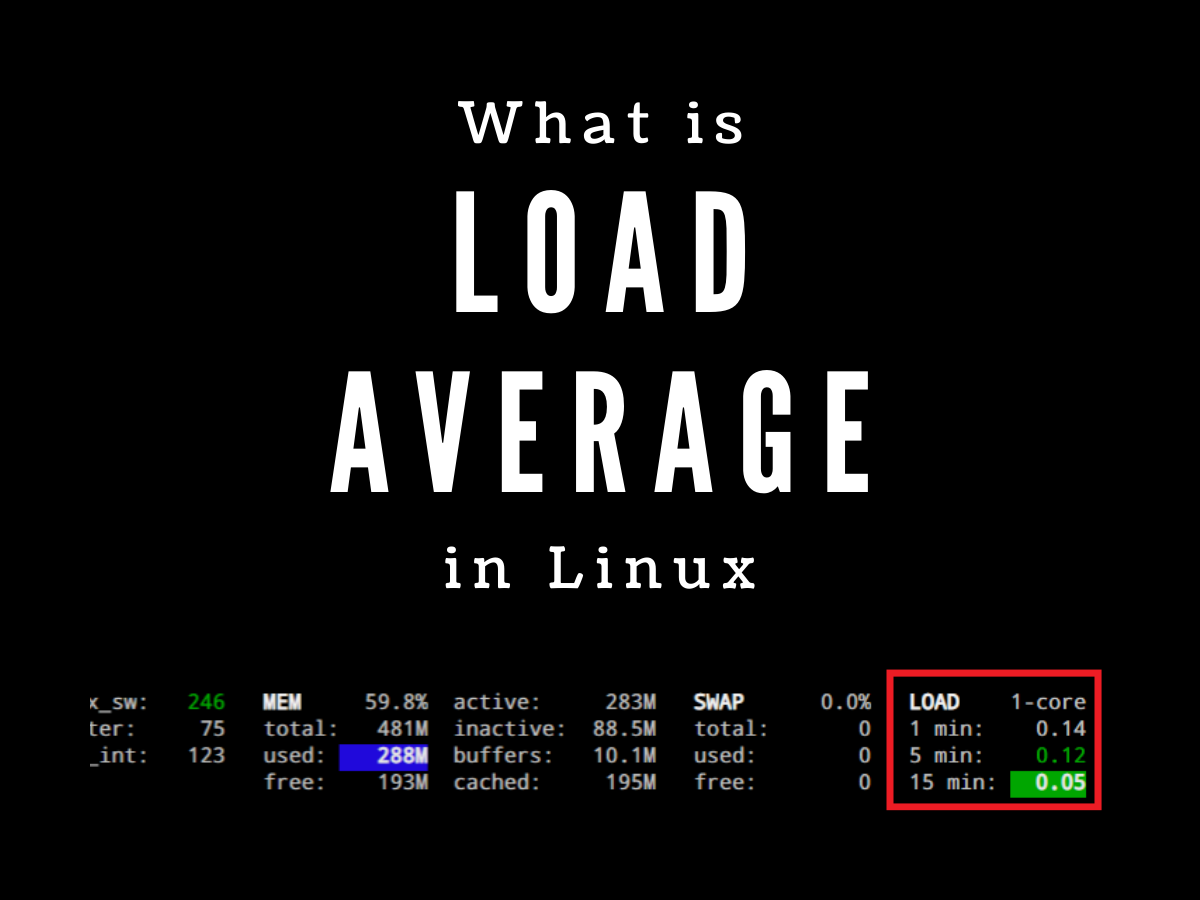
Load average
Résoudre un problème de load average élevé
un peu de contexte, c’est quoi le load average?
A l’origine
On entend souvent parler de load average d’un serveur, mais peu de personnes sont réellement capable de dire de quoi il retourne. En effet à l’origine cette métrique n’est là que pour quantifier la demande faite au CPU: c’est la somme des processus en cours d’exécution et de ceux en attente de traitement. On peut trouver une description du load average dans la RFC546 de Tenex qui date de juillet 1973. Cette définition est toujours d’actualité pour les systèmes UNIX, ou dérivés d’UNIX.
Le cas Linux
Comme rien n’est jamais simple la définition du load average sous linux est quelque peu différente: au début il reflétait les demandes faites au CPU comme pour les autres systèmes d’exploitation. Mais plus tard cette notion a été modifiée afin d’y inclure plus de choses. On va ainsi retrouver dans cette métrique un état des taches exécutables mais aussi des taches dans l’état in interruptible (TASK_UNINTERRUPTIBLE ou nr_uninterruptible). Cela permet de tracer ainsi ce qui se passe pour les taches qui vont être bloquées par des accès disques, des accès réseaux, des manques de mémoires. En général on peut repérer facilement ces processus bloqués à l’aide de la commande top car leur état est positionné sur "D". Le manuel de la commande ps appelle ces taches: "uninterruptible sleep (usualy IO)".
L’ajout de ces processus in interruptible a pour conséquence que le load average peut augmenter à cause d’attente réseau ou disque, et pas seulement de la charge du CPU.
Déterminer le load average maximale de notre machine, la méthode empirique
Il existe plusieurs méthodes pour déterminer le load average maximum que peut atteindre un serveur, cependant il faut aussi tenir compte de l’OS exécuté. Dans le cas de la plupart des systèmes (hors linux) on peut se contenter de regarde combien de cpu sont disponibles et donc en déduire le load average maximale. Dans le cas d’une machine linux on s’accorde à dire que le load average maximale va dépendre du nombre de ressources disponibles sur le serveur. Par ressources on entend CPU, mémoire, disques.
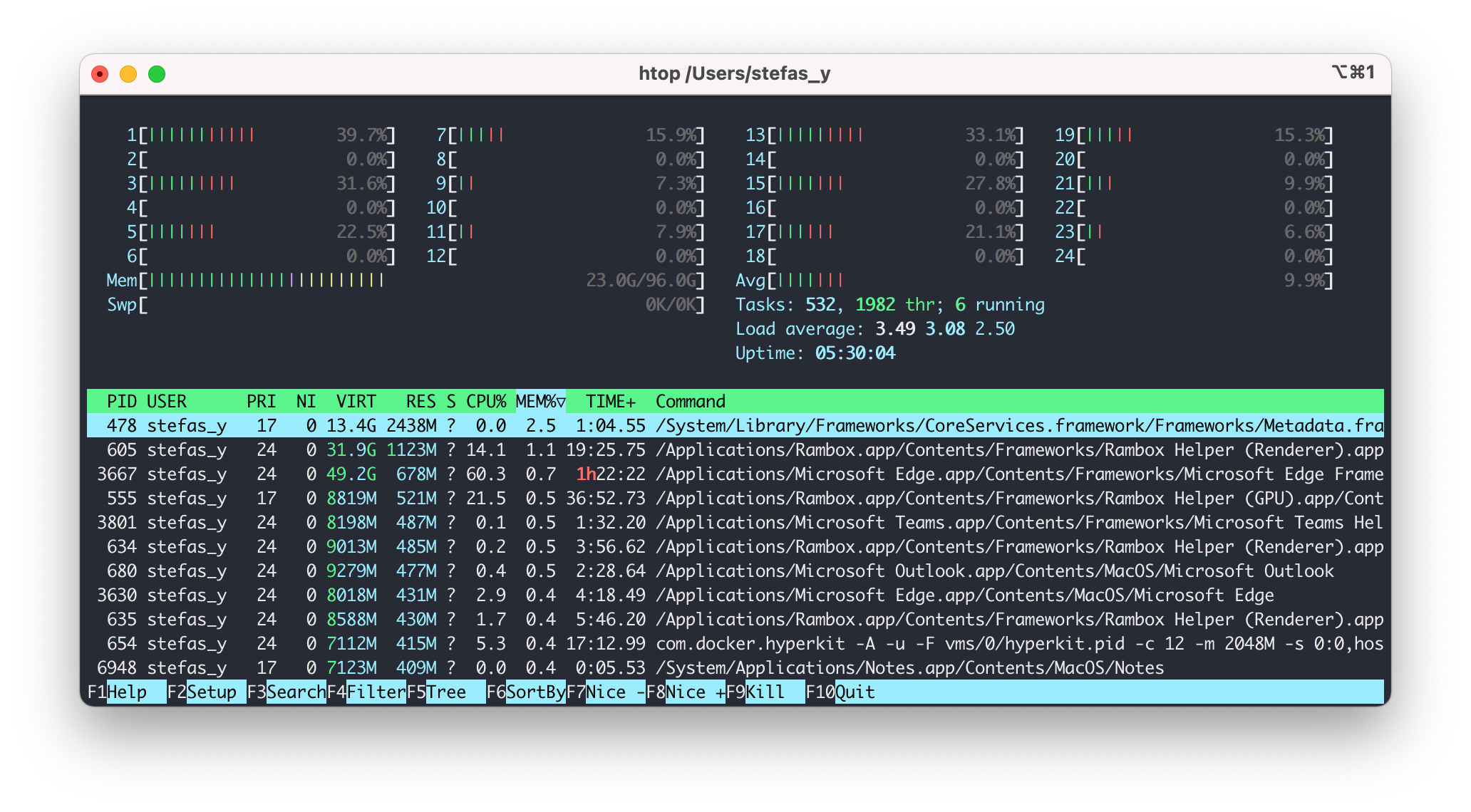
Exemple avec la machine suivante qui contient 24 cpu, de la mémoire, 4 disques durs:
les différents outils à notre disposition
nproc
Cela peut sembler simple, mais la première commande à entrer quand on arrive sur un système ayant une alerte de load average est: nproc. Cette commande va simplement nous renseigner sur le nombre de cœurs CPU disponibles.
root@raspberrypi:~# nproc
4
uptime
Quand on veut connaitre la valeur du load average le premier outil à utiliser est la commande uptime. En voici un exemple d’exécution:
stefas_y@Mac-Pro-de-Yannis ~> uptime
13:51 up 5:07, 2 users, load averages: 1,57 1,78 1,83
stefas_y@Mac-Pro-de-Yannis ~>
Comme on peut le constater cette commande va renvoyer plusieurs informations:
- L’heure actuelle du système
- l’état du système (up)
- le temps écoulé depuis le démarrage du système (ici 5 heures et 7minutes)
- le nombre d’utilisateurs avec une session ouverte
- le load average en moyenne sur la dernière minute, les 5 dernières minutes, et les 15 dernières minutes
top
La commande top présente sur à peu près tous les systèmes permet d »avoir aussi très rapidement une bonne vision de ce qui se passe à l’instant t.
top - 08:08:54 up 97 days, 15:14, 1 user, load average: 0.12, 0.09, 0.02
Tasks: 115 total, 1 running, 114 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 0.3 sy, 0.0 ni, 99.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 974.4 total, 36.9 free, 121.0 used, 816.5 buff/cache
MiB Swap: 100.0 total, 87.5 free, 12.5 used. 744.9 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4264 root 20 0 10188 2832 2468 R 1.0 0.3 0:00.07 top
667 hts 20 0 324636 58852 4720 S 0.3 5.9 1256:58 tvheadend
4229 pi 20 0 12240 3304 2504 S 0.3 0.3 0:00.02 sshd
1 root 20 0 34824 5756 4352 S 0.0 0.6 46:56.51 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:17.24 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
8 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
9 root 20 0 0 0 0 S 0.0 0.0 36:46.05 ksoftirqd/0
10 root 20 0 0 0 0 I 0.0 0.0 19:27.84 rcu_sched
11 root rt 0 0 0 0 S 0.0 0.0 0:02.91 migration/0
12 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/0
13 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/1
14 root rt 0 0 0 0 S 0.0 0.0 0:03.25 migration/1
15 root 20 0 0 0 0 S 0.0 0.0 1:21.36 ksoftirqd/1
18 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/2
Dans l’exemple si dessus:
- la première ligne va nous renseigner sur l’uptime de notre serveur ainsi que sur les valeurs de load average.
- Dans le cas du load average il faut bien garder en tête que les valeurs sont données: sur la dernière minute, les 5 dernières minutes et les 15 dernières minutes.
- La seconde ligne permet de connaitre le nombre de taches tournant sur le système:
- total: donne le nombre de tache total exécutées sur le système.
- running: donne le nombre de tache actuellement en cour d’exécution.
- sleeping: montre le nombre de taches qui sont en exécution mais non active: il s’agit en général des taches de fond du système (driver d’impression, logiciel, etc.…).
- stopped: il s’agit du nombre de taches arrêtées. La valeur ici devrait toujours être à 0 sauf si vous avez envoyé un signal SIGSTOP ou un kill -STOP à un processus. Le fait d’avoir une valeur différente de 0 sur un serveur de production n’est pas normale et demande une investigation.
- zombie: il s’agit là des processus qui serait toujours actif mais dont le processus père a été tué ou a planté. Ici aussi la valeur doit être à 0. Si ce n’est pas le cas une investigation est nécessaire.
- La ligne cpu renseigne sur les statistiques d’usage du processeur:
- us: correspond à l’usage du cpu par les utilisateurs du système.
- sy: correspond à l’usage du cpu fait par le système
- ni: correspond à l’usage du CPU utilisé par les processus sur lesquels un utilisateur aurait utilisé les commandes nice ou renice. En gros cela correspond au processus dont on a modifié la priorité d’exécution.
- id: cette valeur représente le pourcentage du cpu non utilisé. Elle est obtenue par la soustraction à 100 des valeurs us, sy et ni.
- wa: il s’agit des IOWait. Quand un processus ou un programme demande des données, il va d’abord faire un appel au cache du processeur, puis vas ensuite regarder dans la mémoire et enfin ira regarder sur les unités de stockages (disques). Quand la demande arrive sur les unités de stockage, cela va provoquer un temps d’attente avant que le processus ou l’application puisse être exécuté (temps que le thread d’IO finisse de lire les données et qu’elles soient disponible pour le processus ou l’application). En cas de load average élevé il s’agit de la première valeur à regarder, cela signifie souvent que le souci se situe au niveau du stockage qui est trop lent pour les demandes du système.
- hi: signifie "Hard Interrupt", cette valeur indique le pourcentage du cpu consommé par les interruptions matérielles. Dit autrement il s’agit de l’occupation du cpu pour accéder aux différents équipements à l’intérieur du serveur comme le GPU, les cartes réseaux, etc…
- si: il s’agit ici des "Soft Interrupt", cette valeur indique le pourcentage de cpu consommé par lesinterruptions logicielles
- st: c’est probablement la valeur la plus importante dans la liste. Cette valeur indique les IOSteal%. Dans un environnement virtuel, plusieurs serveurs fonctionnent sur un même hyperviseur. On va assigner plusieurs CPU virtuel à chaque machine virtuelle. Il arrive que l’on assigne plus de cpu virtuels que ce qu’il existe de cpu physique à la disposition de l’hyperviseur. Cette valeur va donc indiquer quand il y’a une trop forte consommation de cpu coté hôte (hyperviseur) et que la machine virtuelle ne peut pas utiliser les ressources CPU correctement. On parle de congestion CPU dans ce cas.
A retenir:
- iosteal% permet de mesurer le taux d’occupation de l’hyperviseur.
- iowait% permet de mesurer les performances des disques. Encore une fois dans le cas d’une plateforme virtuelle, il faut regarder les performances du stockage que l’hyperviseur utilise.
htop
Cet outil n’est pas présent par défaut sur toutes les distributions il vous faudra peut-être l’ajouter.
Htop ne vous donnera pas des métriques aussi fines que top par contre il présente l’immense avantage de pouvoir visionner les processus sous forme d’arbre. Ce qui permet de comprendre les relations entre les différents processus.
iotop
iotop est un outil qui comme htop n’est pas présent par défaut sur toutes les distributions. Cet outil vous permettra d’analyser l’usage du stockage en cas d’iowait provoqués par l’accès au stockage. Cet outil permet d’identifier rapidement la ou les applications responsables de l’occupation. Un des gros avantages de iotop c’est qu’il est possible d’avoir une vue avec des métriques qui s’accumulent au cours du temps. Cela permet de trouver rapidement le processus/le thread qui est le plus consommateur sur un laps de temps donné.
Total DISK READ: 5.66 K/s | Total DISK WRITE: 1874.75 K/s
Current DISK READ: 5.66 K/s | Current DISK WRITE: 1328.19 K/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
117342 be/4 www-data 2.24 M 140.00 K 0.00 % 0.07 % php-fpm: pool www
77776 be/4 www-data 1648.00 K 148.00 K 0.00 % 0.06 % php-fpm: pool www
76131 be/4 www-data 812.00 K 144.00 K 0.00 % 0.05 % php-fpm: pool www
77391 be/4 www-data 2.16 M 172.00 K 0.00 % 0.05 % php-fpm: pool www
119235 be/4 www-data 4.00 K 140.00 K 0.00 % 0.05 % php-fpm: pool www
76019 be/4 www-data 2.23 M 132.00 K 0.00 % 0.04 % php-fpm: pool www
75662 be/4 www-data 0.00 B 144.00 K 0.00 % 0.04 % php-fpm: pool www
117022 be/4 www-data 36.00 K 148.00 K 0.00 % 0.04 % php-fpm: pool www
77527 be/4 www-data 0.00 B 144.00 K 0.00 % 0.03 % php-fpm: pool www
117527 be/4 www-data 0.00 B 172.00 K 0.00 % 0.03 % php-fpm: pool www
76064 be/4 www-data 0.00 B 164.00 K 0.00 % 0.03 % php-fpm: pool www
117654 be/4 www-data 48.00 K 144.00 K 0.00 % 0.03 % php-fpm: pool www
113589 be/4 www-data 0.00 B 232.00 K 0.00 % 0.03 % php-fpm: pool www
77747 be/4 www-data 0.00 B 244.00 K 0.00 % 0.03 % php-fpm: pool www
117273 be/4 www-data 0.00 B 136.00 K 0.00 % 0.03 % php-fpm: pool www
77959 be/4 www-data 0.00 B 132.00 K 0.00 % 0.03 % php-fpm: pool www
75848 be/4 www-data 0.00 B 144.00 K 0.00 % 0.03 % php-fpm: pool www
77311 be/4 www-data 0.00 B 128.00 K 0.00 % 0.03 % php-fpm: pool www
75586 be/4 www-data 0.00 B 140.00 K 0.00 % 0.03 % php-fpm: pool www
119130 be/4 www-data 0.00 B 116.00 K 0.00 % 0.03 % php-fpm: pool www
75865 be/4 www-data 0.00 B 224.00 K 0.00 % 0.03 % php-fpm: pool www
117840 be/4 www-data 0.00 B 140.00 K 0.00 % 0.03 % php-fpm: pool www
76123 be/4 www-data 0.00 B 128.00 K 0.00 % 0.03 % php-fpm: pool www
611 be/3 root 0.00 B 14.48 M 0.00 % 0.02 % [jbd2/sdc1-8]
77353 be/4 www-data 0.00 B 112.00 K 0.00 % 0.02 % php-fpm: pool www
keys: any: refresh q: quit i: ionice o: active p: procs a: bandwidth
sort: r: asc left: SWAPIN right: COMMAND home: TID end: COMMAND
mytop
Mytop est l’équivalent de top mais pour un serveur MySQL/maria dB. Cet outil est présent dans les paquets système et n’est pas installé par défaut. A l’instar de top cet outil permet de voir les requêtes en cour d’exécution sur un serveur de base de données. Cela permet d’avancer dans le troubleshooting de load average dans le cas où le processus responsable du load serait maria dB/MySQL.
MySQL on localhost (10.3.27) up 27+03:10:35 [16:08:50]
Queries: 214.5M qps: 96 Slow: 2.4k Se/In/Up/De(%): 29/54/10/02
Sorts: 1954 qps now: 111 Slow qps: 0.0 Threads: 94 ( 7/ 38) 28/57/06/00
Handler: (R/W/U/D) 594729/ 66/ 5/ 0 Tmp: R/W/U: 462/ 864/ 0
ISAM Key Efficiency: 48.3% Bps in/out: 27.0k/ 1.4M Now in/out: 21.5k/ 1.4M
Id User Host/IP DB Time % Cmd State Query
-- ---- ------- -- ---- - --- ----- ----------
1 system u 2344235 0.0 Sleep WSREP aborter i
1590979 infocent ip29 mysql 1928430 0.0 Sleep
1744087 infocent ip29 1906434 0.0 Sleep
1780174 infocent ip29 mysql 1902331 0.0 Sleep
1812342 infocent ip29 mysql 1897769 0.0 Sleep
2169950 infocent ip29 mysql 1837941 0.0 Sleep
2188637 infocent ip29 mysql 1834945 0.0 Sleep
2188575 infocent ip29 mysql 1833821 0.0 Sleep
2646803 infocent ip29 1745744 0.0 Sleep
2647139 infocent ip29 mysql 1745731 0.0 Sleep
2656944 infocent ip29 1744395 0.0 Sleep
2732471 infocent ip29 mysql 1734254 0.0 Sleep
2782011 infocent ip29 mysql 1728432 0.0 Sleep
2936121 infocent ip29 1660512 0.0 Sleep
2965722 infocent ip29 mysql 1656854 0.0 Sleep
3033934 infocent ip29 mysql 1644424 0.0 Sleep
3046469 infocent ip29 1642639 0.0 Sleep
3052840 infocent ip29 mysql 1641386 0.0 Sleep
3085698 infocent ip29 mysql 1636995 0.0 Sleep
3086187 infocent ip29 mysql 1636762 0.0 Sleep
3238841 infocent ip29 mysql 1576838 0.0 Sleep
la suite sysstat
La suite sysstat est probablement l’outil le plus utilisé pour l’étude des performances d’un système. Elle est composée des outils: iostat, pidstat, mpstat, et sar.
-
mpstat pour les statistiques processeur: cet outil permet de voir l’usage du ou des CPU sur le système:
- l’option P (processor number) permet d’afficher les statistiques pour un ou plusieurs CPU. On peut utiliser ALL pour voir les informations de tous les CPUs.
root@top:~# mpstat Linux 4.15.0-147-generic (top) 07/06/21 _x86_64_ (2 CPU) 16:46:15 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 16:46:15 all 0.84 0.08 0.39 0.05 0.00 0.01 0.00 0.00 0.00 98.62 root@top:~# mpstat -P ALL Linux 4.15.0-147-generic (top) 07/06/21 _x86_64_ (2 CPU) 16:46:19 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 16:46:19 all 0.84 0.08 0.39 0.05 0.00 0.01 0.00 0.00 0.00 98.62 16:46:19 0 1.00 0.02 0.44 0.06 0.00 0.01 0.00 0.00 0.00 98.47 16:46:19 1 0.68 0.14 0.34 0.05 0.00 0.01 0.00 0.00 0.00 98.78- pour afficher les statistiques pour un nombre donné d’itérations pour un intervalle de temps donnée il suffit de passer les valeurs en option de la commande
root@top:~# mpstat -P ALL 2 3 Linux 4.15.0-147-generic (top) 07/06/21 _x86_64_ (2 CPU) 16:47:35 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 16:47:37 all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 16:47:37 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 16:47:37 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 16:47:37 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 16:47:39 all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 16:47:39 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 16:47:39 1 0.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 99.50 16:47:39 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 16:47:41 all 0.25 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.75 16:47:41 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 16:47:41 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00- l’option I affichera les statistiques d’interruptions par processeur
root@top:~# mpstat -I ALL Linux 4.15.0-147-generic (top) 07/06/21 _x86_64_ (2 CPU) 16:56:08 CPU intr/s 16:56:08 all 82.30 16:56:08 CPU 0/s 1/s 8/s 9/s 12/s 14/s 15/s 16/s 24/s 25/s 26/s 27/s 28/s 29/s 30/s 31/s 32/s 33/s 34/s 35/s 36/s 37/ s 38/s 39/s 40/s 41/s 42/s 43/s 44/s 45/s 46/s 47/s 48/s 49/s 50/s 51/s 52/s 53/s 54/s 55/s 56/s 57/s 58/s 59/s 60/ s 61/s 62/s NMI/s LOC/s SPU/s PMI/s IWI/s RTR/s RES/s CAL/s TLB/s TRM/s THR/s DFR/s MCE/s MCP/s ERR/s MIS/s PIN/s NPI/s PIW/s 16:56:08 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0. 00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.51 3.62 0.49 0.00 1. 57 0.10 0.00 0.00 23.23 0.00 0.00 0.00 0.00 5.66 2.66 0.06 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 16:56:08 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0. 00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.03 0.03 0.02 0.00 1. 78 0.03 0.00 0.00 36.65 0.00 0.00 0.00 0.00 4.11 1.79 0.04 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 16:56:08 CPU HI/s TIMER/s NET_TX/s NET_RX/s BLOCK/s IRQ_POLL/s TASKLET/s SCHED/s HRTIMER/s RCU/s 16:56:08 0 0.00 12.16 0.19 4.11 1.59 0.00 0.16 9.96 0.00 19.25 16:56:08 1 0.00 30.73 0.00 0.07 1.96 0.00 0.03 28.89 0.00 27.75- l’option A permet d’afficher toutes les informations c’est l’équivalent de "-u -I ALL -p ALL"
root@top:~# mpstat -A Linux 4.15.0-147-generic (top) 07/06/21 _x86_64_ (2 CPU) 16:57:45 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 16:57:45 all 0.73 0.07 0.35 0.05 0.00 0.01 0.00 0.00 0.00 98.80 16:57:45 0 0.87 0.02 0.39 0.05 0.00 0.01 0.00 0.00 0.00 98.66 16:57:45 1 0.59 0.12 0.30 0.04 0.00 0.01 0.00 0.00 0.00 98.94 16:57:45 NODE %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 16:57:45 all 0.73 0.07 0.35 0.05 0.00 0.01 0.00 0.00 0.00 98.80 16:57:45 0 0.73 0.07 0.35 0.05 0.00 0.01 0.00 0.00 0.00 98.69 16:57:45 CPU intr/s 16:57:45 all 81.76 16:57:45 0 47.97 16:57:45 1 87.95 16:57:45 CPU 0/s 1/s 8/s 9/s 12/s 14/s 15/s 16/s 24/s 25/s 26/s 27/s 28/s 29/s 30/s 31/s 32/s 33/s 34/s 35/s 36/s 37/ s 38/s 39/s 40/s 41/s 42/s 43/s 44/s 45/s 46/s 47/s 48/s 49/s 50/s 51/s 52/s 53/s 54/s 55/s 56/s 57/s 58/s 59/s 60/ s 61/s 62/s NMI/s LOC/s SPU/s PMI/s IWI/s RTR/s RES/s CAL/s TLB/s TRM/s THR/s DFR/s MCE/s MCP/s ERR/s MIS/s PIN/s NPI/s PIW/s 16:57:45 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0. 00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.51 3.57 0.48 0.00 1. 54 0.10 0.00 0.00 23.57 0.00 0.00 0.00 0.00 5.67 2.60 0.06 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 16:57:45 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0. 00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.03 0.03 0.02 0.00 1. 74 0.03 0.00 0.00 36.06 0.00 0.00 0.00 0.00 4.03 1.76 0.04 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 16:57:45 CPU HI/s TIMER/s NET_TX/s NET_RX/s BLOCK/s IRQ_POLL/s TASKLET/s SCHED/s HRTIMER/s RCU/s 16:57:45 0 0.00 12.49 0.19 4.05 1.57 0.00 0.16 10.33 0.00 19.18 16:57:45 1 0.00 30.22 0.00 0.06 1.92 0.00 0.03 28.42 0.00 27.29 -
pidstat: pour les statistiques relatives aux processus et aux threads du noyau.
- l’invoquer sans argument permet d’afficher les taches actives
root@top:~# pidstat Linux 4.15.0-147-generic (top) 07/06/21 _x86_64_ (2 CPU) 17:30:57 UID PID %usr %system %guest %wait %CPU CPU Command 17:30:57 0 1 0.01 0.04 0.00 0.01 0.05 0 systemd 17:30:57 0 7 0.00 0.00 0.00 0.00 0.00 0 ksoftirqd/0 17:30:57 0 8 0.02 0.00 0.00 0.01 0.02 1 rcu_sched 17:30:57 0 11 0.00 0.00 0.00 0.00 0.00 0 watchdog/0 17:30:57 0 14 0.00 0.00 0.00 0.00 0.00 1 watchdog/1 17:30:57 0 15 0.00 0.00 0.00 0.00 0.00 1 migration/1 17:30:57 0 16 0.00 0.00 0.00 0.01 0.00 1 ksoftirqd/1 17:30:57 0 24 0.00 0.00 0.00 0.00 0.00 1 khungtaskd 17:30:57 0 87 0.00 0.00 0.00 0.00 0.00 0 scsi_eh_0 17:30:57 0 89 0.00 0.00 0.00 0.00 0.00 1 scsi_eh_1 17:30:57 0 288 0.00 0.00 0.00 0.00 0.00 1 kworker/1:1H 17:30:57 0 316 0.00 0.00 0.00 0.00 0.00 0 kworker/0:1H 17:30:57 0 437 0.00 0.00 0.00 0.00 0.00 1 jbd2/sda2-8 17:30:57 0 512 0.00 0.01 0.00 0.01 0.01 0 systemd-journal 17:30:57 0 523 0.01 0.00 0.00 0.03 0.01 1 systemd-udevd 17:30:57 0 561 0.00 0.00 0.00 0.00 0.00 1 loop1- l’option p (process) permet d’afficher à la fois les tache active et non active
root@top:~# pidstat -p ALL Linux 4.15.0-147-generic (top) 07/06/21 _x86_64_ (2 CPU) 17:33:01 UID PID %usr %system %guest %wait %CPU CPU Command 17:33:01 0 1 0.01 0.04 0.00 0.00 0.05 0 systemd 17:33:01 0 2 0.00 0.00 0.00 0.00 0.00 0 kthreadd 17:33:01 0 4 0.00 0.00 0.00 0.00 0.00 0 kworker/0:0H 17:33:01 0 6 0.00 0.00 0.00 0.00 0.00 0 mm_percpu_wq 17:33:01 0 7 0.00 0.00 0.00 0.00 0.00 0 ksoftirqd/0 17:33:01 0 8 0.02 0.00 0.00 0.01 0.02 1 rcu_sched 17:33:01 0 9 0.00 0.00 0.00 0.00 0.00 0 rcu_bh 17:33:01 0 10 0.00 0.00 0.00 0.00 0.00 0 migration/0 17:33:01 0 11 0.00 0.00 0.00 0.00 0.00 0 watchdog/0 17:33:01 0 12 0.00 0.00 0.00 0.00 0.00 0 cpuhp/0 17:33:01 0 13 0.00 0.00 0.00 0.00 0.00 1 cpuhp/1 17:33:01 0 14 0.00 0.00 0.00 0.00 0.00 1 watchdog/1 17:33:01 0 15 0.00 0.00 0.00 0.00 0.00 1 migration/1 17:33:01 0 16 0.00 0.00 0.00 0.00 0.00 1 ksoftirqd/1 17:33:01 0 18 0.00 0.00 0.00 0.00 0.00 1 kworker/1:0H 17:33:01 0 19 0.00 0.00 0.00 0.00 0.00 1 kdevtmpfs 17:33:01 0 20 0.00 0.00 0.00 0.00 0.00 1 netns 17:33:01 0 21 0.00 0.00 0.00 0.00 0.00 1 rcu_tasks_kthre 17:33:01 0 22 0.00 0.00 0.00 0.00 0.00 1 kauditd 17:33:01 0 24 0.00 0.00 0.00 0.00 0.00 1 khungtaskd 17:33:01 0 25 0.00 0.00 0.00 0.00 0.00 1 oom_reaper 17:33:01 0 26 0.00 0.00 0.00 0.00 0.00 1 writeback 17:33:01 0 27 0.00 0.00 0.00 0.00 0.00 1 kcompactd0 17:33:01 0 28 0.00 0.00 0.00 0.00 0.00 1 ksmd 17:33:01 0 29 0.00 0.00 0.00 0.00 0.00 1 khugepaged 17:33:01 0 30 0.00 0.00 0.00 0.00 0.00 1 crypto- l’option d permet d’avoir les statistiques IO rafraichit toutes les n secondes
root@top:~# pidstat -d 2 Linux 4.15.0-147-generic (top) 07/06/21 _x86_64_ (2 CPU) 17:35:21 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 17:35:23 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 17:35:25 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command 17:35:27 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command- pour connaitre les statistiques cpu en même temps que les threads pour un processus donné, sur un intervalle de 2 secondes 3 fois consécutives il faut utiliser l’option t
root@top:~# pidstat -t -p 8752 2 3 Linux 4.15.0-147-generic (top) 07/06/21 _x86_64_ (2 CPU) 17:39:15 UID TGID TID %usr %system %guest %wait %CPU CPU Command 17:39:17 0 8752 - 0.00 0.00 0.00 0.00 0.00 1 sshd 17:39:17 0 - 8752 0.00 0.00 0.00 0.00 0.00 1 |__sshd 17:39:17 UID TGID TID %usr %system %guest %wait %CPU CPU Command 17:39:19 0 8752 - 0.00 0.00 0.00 0.00 0.00 1 sshd 17:39:19 0 - 8752 0.00 0.00 0.00 0.00 0.00 1 |__sshd 17:39:19 UID TGID TID %usr %system %guest %wait %CPU CPU Command 17:39:21 0 8752 - 0.00 0.00 0.00 0.00 0.00 1 sshd 17:39:21 0 - 8752 0.00 0.00 0.00 0.00 0.00 1 |__sshd Average: UID TGID TID %usr %system %guest %wait %CPU CPU Command Average: 0 8752 - 0.00 0.00 0.00 0.00 0.00 - sshd Average: 0 - 8752 0.00 0.00 0.00 0.00 0.00 - |__sshd- si vous voulez connaitre l’usage mémoire vous pouvez utiliser l’option rh, il est possible d’utiliser cette option en plus de celles permettant de suivre un processus pendant un intervalle de temps donnée et un nombre d’occurrences données.
root@top:~# pidstat -rh 2 3 Linux 4.15.0-147-generic (top) 07/06/21 _x86_64_ (2 CPU) # Time UID PID minflt/s majflt/s VSZ RSS %MEM Command 17:43:45 0 9240 553.23 0.00 11520 6016 0.30 pidstat # Time UID PID minflt/s majflt/s VSZ RSS %MEM Command 17:43:47 0 9240 51.00 0.00 11520 6280 0.31 pidstat # Time UID PID minflt/s majflt/s VSZ RSS %MEM Command- il est possible aussi d’obtenir une liste de processus en fonction d’un search pattern à l’aide de l’option G
root@top:~# pidstat -G ssh Linux 4.15.0-147-generic (top) 07/06/21 _x86_64_ (2 CPU) 17:44:56 UID PID %usr %system %guest %wait %CPU CPU Command 17:44:56 0 1330 0.00 0.00 0.00 0.00 0.00 1 sshd 17:44:56 0 1689 0.00 0.00 0.00 0.00 0.00 1 sshd 17:44:56 1000 1805 0.00 0.00 0.00 0.00 0.00 1 sshd 17:44:56 0 6150 0.00 0.00 0.00 0.00 0.00 0 sshd 17:44:56 1000 6245 0.00 0.00 0.00 0.00 0.00 0 sshd 17:44:56 0 8752 0.00 0.00 0.00 0.00 0.00 1 sshd 17:44:56 1000 8822 0.00 0.00 0.00 0.00 0.00 0 sshd- enfin pour avoir les informations de priorité et de planification il est possible d’utiliser l’option R
root@top:~# pidstat -R Linux 4.15.0-147-generic (top) 07/06/21 _x86_64_ (2 CPU) 17:46:04 UID PID prio policy Command 17:46:04 0 10 99 FIFO migration/0 17:46:04 0 11 99 FIFO watchdog/0 17:46:04 0 14 99 FIFO watchdog/1 17:46:04 0 15 99 FIFO migration/1 17:46:04 0 196 50 FIFO irq/16-vmwgfx -
iostat: permet de remonter des statistiques à la fois sur le cpu et les IOs (matériel/partitions). S’il est invoqué sans argument, il affiche l’usage cpu ainsi que les statistiques IOs pour les partitions.
~# iostat Linux 4.19.0-16-amd64 (swarm1) 08/07/2021 _x86_64_ (6 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 3,87 0,00 3,02 0,31 0,00 92,80 Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn sdb 6,04 162,77 294,36 410381277 742131048 sda 8,32 21,27 147,36 53622558 371521204 sdc 23,02 357,95 550,74 902470845 1388522344 scd0 0,00 0,00 0,00 1040 0- l’option c permet de n’afficher que les informations relatives à l’usage CPU
~# iostat -c Linux 4.19.0-16-amd64 (swarm1) 08/07/2021 _x86_64_ (6 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 3,87 0,00 3,02 0,31 0,00 92,80- l’option d permet de n’afficher que les informations relatives aux I/O des partitions:
~# iostat -d Linux 4.19.0-16-amd64 (swarm1) 08/07/2021 _x86_64_ (6 CPU) Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn sdb 6,04 162,76 294,34 410381357 742140512 sda 8,32 21,27 147,39 53622682 371620240 sdc 23,03 357,93 550,97 902471309 1389192100 scd0 0,00 0,00 0,00 1040 0- Il est possible de ne sélectionner qu’un seul périphérique à l’aide de l’option p
~# iostat -p sda Linux 4.19.0-16-amd64 (swarm1) 08/07/2021 _x86_64_ (6 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 3,87 0,00 3,02 0,31 0,00 92,80 Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda 8,32 21,27 147,40 53622686 371650920 sda2 3,72 6,41 10,47 16151324 26401520 sda3 4,60 14,86 136,93 37463537 345249372 sda1 0,00 0,00 0,00 4721 28- enfin l’option N permet d’avoir les statistiques lvm
~# iostat -N Linux 5.3.18-3-pve (bigballs-for-the-win) 07/08/2021 _x86_64_ (24 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 1.91 0.00 1.09 0.01 0.00 96.98 Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda 106.24 666.57 485.31 24608310844 17916632856 pve-swap 0.00 0.00 0.00 3264 0 pve-root 1.91 0.14 19.57 5001489 722524636 pve-data_tmeta 0.43 0.68 1.03 25276004 37971276 pve-data_tdata 114.22 567.47 464.71 20949628372 17156062174 pve-data-tpool 114.22 567.47 464.71 20949628372 17156062174 pve-vm--101--disk--0 0.00 0.00 0.00 3132 0 pve-vm--102--cloudinit 0.00 0.00 0.00 348 0 pve-vm--308--disk--0 0.03 0.01 0.23 264219 8483881 pve-vm--308--cloudinit 0.00 0.00 0.00 1252 356 pve-vm--108--disk--0 86.82 560.52 208.99 20693137570 7715629810 pve-vm--108--cloudinit 0.00 0.00 0.00 1012 356 pve-vm--112--disk--0 0.21 0.14 2.49 5083533 91944510 pve-vm--114--cloudinit 0.00 0.00 0.00 1012 356 pve-vm--112--cloudinit 0.00 0.00 0.00 2800 1068 pve-vm--114--disk--0 0.20 0.07 2.10 2590114 77593365 pve-base--103--disk--0 0.00 0.00 0.00 11484 0 pve-vm--103--cloudinit 0.00 0.00 0.00 116 0 pve-vm--117--disk--0 3.19 1.02 23.83 37487887 879747074 pve-vm--117--cloudinit 0.00 0.00 0.00 1012 356 pve-base--102--disk--0 0.01 0.28 0.00 10490980 0 pve-vm--100--cloudinit 0.00 0.00 0.00 116 0 pve-vm--131--cloudinit 0.00 0.00 0.00 1012 356 pve-vm--131--disk--0 0.25 0.05 2.46 1958223 90713769 pve-vm--133--cloudinit 0.00 0.00 0.00 1012 356 pve-vm--133--disk--0 0.04 0.05 0.41 1921867 15136165 -
vmstat: permet d’avoir des informations fines sur l’usage de la mémoire.
- invoquer la commande sans argument ou avec l’option a vous permettra de voir rapidement l’usage instantané de la mémoire sur le système
~# vmstat -a procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free inact active si so bi bo in cs us sy id wa st 0 0 1309696 948128 1627004 9279000 0 0 201 424 1 4 10 0 90 0 0- comme pour les autres commandes il est possible de demander une exécution à intervalle de temps régulier et pour une durée déterminée: la commande suivante demande 6 exécutions espacées de 2 secondes:
:~# vmstat 2 6 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 1309696 903468 212388 939368 0 0 201 424 1 4 10 0 90 0 0 0 0 1309696 903204 212428 939476 0 0 0 954 950 1135 12 0 87 0 0 0 0 1309696 903204 212452 939496 0 0 0 2252 778 789 2 0 98 0 0 0 0 1309696 902508 212468 939500 0 0 0 888 819 1020 1 0 99 0 0 0 0 1309696 902188 212500 939752 0 0 0 224 1696 1925 3 0 97 0 0 0 0 1309696 902124 212532 939772 0 0 8 1194 783 845 8 0 91 0 0- l’option t permettra d’afficher le timestamp lors des mesures
~# vmstat -t 2 6 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- -----timestamp----- r b swpd free buff cache si so bi bo in cs us sy id wa st CEST 1 0 1309696 895572 213896 943756 0 0 201 424 1 4 10 0 90 0 0 2021-07-07 16:39:32 0 0 1309696 895516 213908 943772 0 0 0 826 1043 1450 22 0 78 0 0 2021-07-07 16:39:34 0 0 1309696 895392 213932 943916 0 0 8 310 1227 1383 5 0 95 0 0 2021-07-07 16:39:36 0 0 1309696 895036 213948 943940 0 0 8 534 700 793 6 0 94 0 0 2021-07-07 16:39:38 0 0 1309696 894924 213980 943964 0 0 56 700 861 850 11 1 89 0 0 2021-07-07 16:39:40 0 0 1309696 894868 213988 943980 0 0 0 12 633 565 9 0 91 0 0 2021-07-07 16:39:42- la commande s affiche un tableau des différentes informations
~# vmstat -s 12275224 K total memory 10216396 K used memory 9289748 K active memory 1668172 K inactive memory 896088 K free memory 215084 K buffer memory 947656 K swap cache 6288380 K total swap 1309696 K used swap 4978684 K free swap 93744351 non-nice user cpu ticks 119757 nice user cpu ticks 4050375 system cpu ticks 872442942 idle cpu ticks 452601 IO-wait cpu ticks 0 IRQ cpu ticks 665718 softirq cpu ticks 0 stolen cpu ticks 1954272226 pages paged in 4121047236 pages paged out 151477 pages swapped in 495181 pages swapped out 523436877 interrupts 2614511763 CPU context switches 1623234938 boot time 3838821 forks- la commande d vous donnera les infos de tous les périphériques de type bloc
~# vmstat -d disk- ------------reads------------ ------------writes----------- -----IO------ total merged sectors ms total merged sectors ms cur sec sdb 80283023 11977 3393218218 24222529 120889926 10585187 6816646536 15494449 0 12743 sdd 1167906 0 280838826 247098 3155490 1600335 864866624 7868424 0 582 sda 224215 90031 10382070 40163 117770 95014 6220280 85010 0 63 sdc 884027 69 224106618 176764 1816924 1298942 554650848 973300 0 429 sr0 27 0 2080 5 0 0 0 0 0 0- enfin S vous permet d’afficher dans différentes tailles: Mégabytes, mégabit, Kilo bytes, kilobit
~# vmstat -S M 1 3 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 1279 854 212 937 0 0 201 424 1 4 10 0 90 0 0 0 0 1279 850 212 937 0 0 0 18916 3133 3091 4 1 95 0 0 1 0 1279 849 212 937 0 0 0 2576 5011 1639 11 1 88 0 0
Mon couteau suisse favoris: atop
Cet outil n’est en général pas fourni avec les distributions par défaut, par contre il est souvent présent dans les paquets des distributions:
-
pour les distributions basées sur redhat il faut activer le dépôt epel et ensuite ajouter l’outil atop
dnf install epel-release -y dnf install atop -y -
pour les distributions basées sur Debian l’outil est normalement déjà présent dans les paquets officiels
apt install atop
Pour utiliser atop, il vous suffit de l’invoquer:
atop
Quand vous exécutez atop sans arguments particulier il va vous montrer l’usage du CPU, de la mémoire, du swap, des disques et du réseau à un intervalle de 10 secondes. Dans la partie basse de la fenêtre vous pourrez vois pour chaque processus ou thread: l’usager cpu, la consommation mémoire, les I/Os disques, la priorité, le username ayant lancé la tâche, l’état et même le code de sortie.
Personnellement je préfère l’invoquer avec les options -Aac, en l’exécutant avec ces arguments et en le laissant tourner quelques secondes on aura des métriques agrégées de ce qui se passe sur le serveur, permettant ainsi un troubleshooting plus simple et rapide.
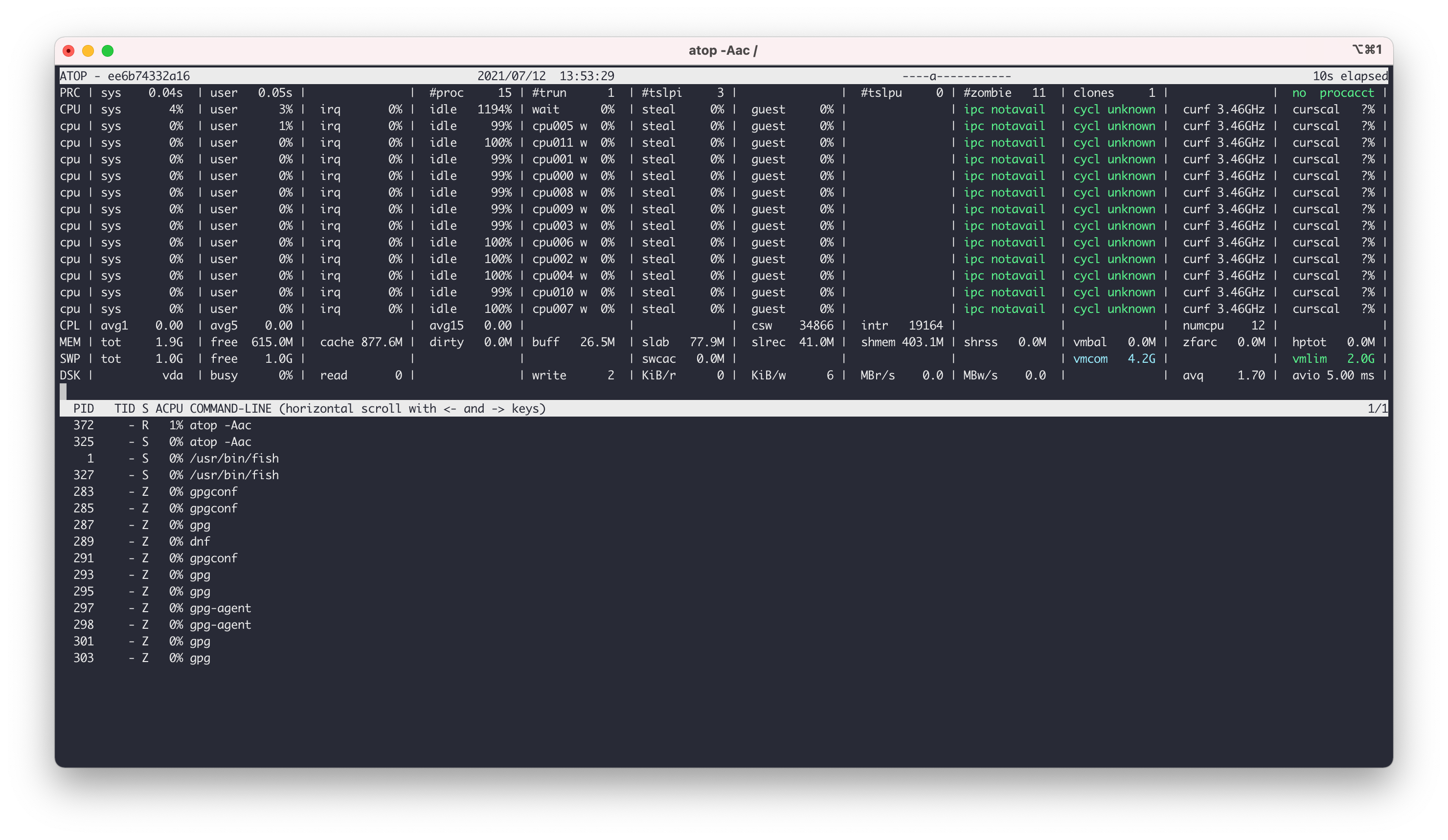
Dans la partie haute de la fenêtre vous pourrez trouver toutes les métriques relatives aux CPUs, RAM, SWAP, Utilisation des DISK, utilisation des cartes NETWORK. CPL représente le load average du serveur. Il est donc possible en attendant un peu d’avoir une bonne vision des consommations de ressources sur le serveur.
La partie basse de la fenêtre permet de voir les différents processus en cours d’exécution.
Il est à noter que cet outil vous affichera des couleurs si votre terminal le permet, vous permettant de voir rapidement où se situe le souci.
Je vous invite très fortement à lire le man de cet outil afin de voir tout ce qu’il est possible d’en obtenir.
Étude d’un cas de load average élevé
En cas d’alerte pour load average sur un serveur il faut savoir que l’on doit agir rapidement. En effet plus le temps passe et plus on court le risque de perdre le serveur au point de ne pouvoir le récupérer qu’à laide d’un reboot electrique. En gardant en tête qu’un redémarrage n’est pas la solution. La cause du load avrage elevé a de fortes chances d’être toujours présente et de provoquer à nouveau un load average élevé.
Méthodologie
Ressevoir une alerte de de load average signifie qu’au moins une des ressources du serveur est maltraitée. Il peut donc s’agir de la RAM, de l’utilisation du CPU, des I/Os, etc…
- on cherche à déterminer qu’elle est la ressources surchargée.
- on cherche quel est le service responsable de l’usage de cette ressource.
- On cherche ce qui et responsable de l’usage de ce service.
En pratique
Comme vu plus haut il existe de nombreux outils à notre disposition:
- A l’ancienne
- On commence par lancer la commande top et on fait attention aux valeurs les plus importantes en fonction de notre environnement: %st, %wa, %us, etc…
- Une fois que l’on connait la ressources consommée on va utiliser l’outil qui va le mieux pour regarder ce qui se passe et essayer de trouver quel service utilise notre ressource.
Laisser un commentaire